
In a nutshell:
- Traditional data science methods are slow and inefficient, hindering valuable insights.
- Low-code AI tools streamline data cleaning, model building, and iteration processes.
- Stakeholder alignment, domain expertise, and data wrangling are major challenges in traditional data science.
- Modern AI tools empower data professionals to focus on strategy and build more robust models.
- By prioritizing AI-powered data science tools, organizations can future-proof their data analytics and enhance their team’s careers.
It’s the 1960s. Pioneering data scientists just launched the IBM System/360, a groundbreaking (and expensive) feat of computing and data science. The System/360, a marvel for its time, introduced a new era of standardization. Fast-forward 60 years, and traditional, manual data science still dominates many analytics teams, hindering results in a fast-paced, data-rich reality.
The good news? We’ve entered a new golden age of data science. Modern AI tools are putting data science on hyper-speed, streamlining the path to valuable insights. Data professionals can now reclaim hours previously spent on data cleaning, feature engineering, and building and training models, allowing them to focus on the strategic analysis and data-driven decision-making that drives business value.
If you’re thinking about shifting gears and unleashing the full potential of your data through AI, here’s a breakdown between manual data science techniques and automated data science powered by AI.
Is a traditional approach to data science limiting your organization’s potential?
Why traditional data science is holding you back
Traditional data science can feel like driving a stick-shift car in a world of racecars. That’s because manual data science relies heavily on processes like:
- Manual data wrangling that’s tedious and inefficient. Especially for messy data sets, data wrangling often involves manually searching for, collecting, and cleaning data from various sources.
- Hand-coded models that are time-consuming and prone to errors. Think about building a model from scratch in Python, writing extensive code for each step, selecting features, and training algorithms.
- Limited domain knowledge where data scientists and analysts may not fully understand the business context. This can lead to misinterpretations of the data and choosing and building models that don’t address or aren’t optimized for actual business needs — this approach also doesn’t allow for rapid iteration or experimentation.
These factors all contribute to one major problem: slowness.
Let’s look at several of these factors in a bit more detail.
Why traditional methods take so long (and how low-code platforms help)
Stakeholder alignment
Defining the right question for a data science project often involves repeated back-and-forth discussions with stakeholders from different departments. These stakeholders might have different priorities and levels of data literacy, making it challenging to finally arrive at a well-defined question that sets the project up for success.
Pecan’s Predictive GenAI guides users toward what’s called a predictive question. This interactive process helps data analysts and stakeholders collaborate on formulating the right question. Pecan guides users through a series of prompts and questions, ensuring the chosen question is clear, feasible, and directly related to a business need.
Domain expertise
Traditionally, data science projects rely heavily on data scientists who might not have the same deep understanding of the specific business context as data analysts who are closer to the day-to-day operations or specific department members. This can lead to inefficiencies and misinterpretations of the data.
Pecan’s user-friendly interface and guided functionalities allow data analysts, even with limited data science expertise, to leverage the power of AI for predictive modeling. This fosters closer collaboration and ensures the chosen models directly address business needs.
Data wrangling
Finding the right data can be like searching for a needle in a haystack—you have to spend hours cleaning the needle. A 2016 Forbes survey showed a breakdown of how data scientists spend their time and revealed that they spend a whopping 80% of their time just preparing data. Not much has changed between then and today.
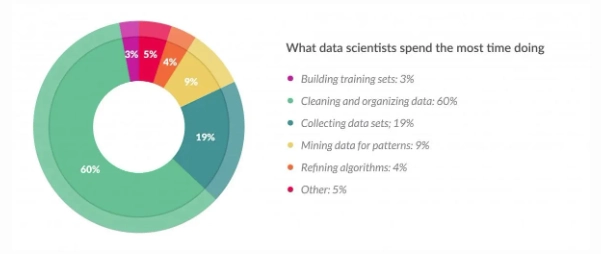
Source: “Cleaning Big Data: Most Time-Consuming, Least Enjoyable Data Science Task, Survey Says,” Forbes
Built-in automated data cleansing features in Pecan significantly simplify the data cleaning and scrubbing processes. Pecan can automatically connect to various data sources, identify relevant data sets based on your needs, and handle much of the tedious cleaning and preparation tasks, like handling missing values and formatting inconsistencies. This frees up data scientists and analysts to focus on the more strategic aspects of the project, like feature engineering and model selection, ultimately getting to valuable insights faster.
Model building and iteration
Traditionally, building and refining data science models is a manual and time-consuming process. Data scientists have to write code, test different algorithms, and continuously train and iterate based on the results. This trial-and-error approach can feel slow and frustrating.
Pecan makes model building and rapid iteration a breeze. A library of prebuilt models and algorithms helps your team easily adapt to different business problems. Pecan even offers automated processes to train and test models, allowing for rapid iteration and optimization.
How low-code predictive platforms turn data teams into data scientists
Modern low-code analytics platforms are becoming table stakes for organizations. Not only can they be a main driver of digital transformation, but they’re also a game-changer for building best-in-class data teams.
An MIT Sloan article highlights a crucial point for building a successful data team: the right tools. Today’s data professionals crave user-friendly tools that make their jobs easier. While data scientists are highly skilled, their training often focuses on mechanics rather than limitations. This can lead to overlooking issues like generalizability (a model’s ability to perform well beyond its training data) and choosing readily available but potentially unsuitable data sets.

Today’s AI platforms have significant advantages over the manual processes of yesterday.
This is where modern AI tools with built-in features for data quality checks, generalizability analysis, and user-friendliness come in. These tools empower data professionals to:
- Focus on strategy, not mechanics: By automating tedious tasks like data cleaning and feature engineering, modern tools free up data scientists and analysts to focus on higher-level strategic thinking.
- Build more robust models: Features like generalizability analysis within Pecan help data professionals identify potential weaknesses in their models (like overfitting or underfitting) before deployment.
- Leverage “the right data”: AI tools can integrate with various data sources, making it easier for data professionals to find and use only the most relevant data sets for their projects.
By prioritizing a modern tech stack with AI-powered data science tools, you’re not just making life easier for your data team — you’re future-proofing the company’s data analytics. (And your team’s careers.)
Build your dream team today
There’s a faster path to achieving success in your data organization. Modern predictive analytics tools are a powerful addition to any data team, and they complement the expertise of data professionals and data scientists alike.
Low-code AI tools today go beyond predictive models. They can leverage the power of generative AI and automated machine learning to create entirely new possibilities. This fusion of technologies unlocks even greater value from your data, creating a new level of value for businesses and data professionals.
Ready to take control of your data science projects? See how Pecan can help! Get a demo now.






