

In 1976, a British statistician named George Box wrote the famous line “All models are wrong, some are useful.” He suggested we should focus more on how models can be applied to provide value in a useful manner, rather than debating endlessly if the predictions are all correct or not. But, how can we determine if a model is useful or not?
Pecan’s platform empowers data analysts, especially those without machine-learning experience, to build models from raw data sourced from various origins, using only SQL queries. A model in Pecan can be constructed in just a few hours, which eliminates the need to spend months on data collection, cleanup, and preparation.
However, getting to a trained model is merely the initial step. Model evaluation, repeated iterations, and optimizations can also be time-consuming. This can be particularly challenging for data analysts unfamiliar with machine-learning concepts.
To guide model evaluation, Pecan offers a set of automated health checks that ease the process of ensuring the model’s reliability, combined with actionable recommendations to address possible issues. Those health checks provide a comprehensive evaluation approach that is essential for machine learning models. The checks include a comparison to benchmarks, leakage detection, overfit assessment, label drift detection, and data volume analysis. The checks also provide suggestions for how you can address any issues with the model that are identified.
Health Check #1: Benchmark Comparison
What is a good model? A common mistake is believing that every model with 70-80% accuracy is a good model, and a model with accuracy below that is bad. Let’s understand why this approach is wrong:
- Each model should be tested with the relevant KPI that best serves the intended action that will be derived from using the predictions.
- The model should always be tested against the alternatives.
In this post, we’ll focus on how to determine the model’s value by evaluating it against the alternatives, or in other words, the benchmarks.
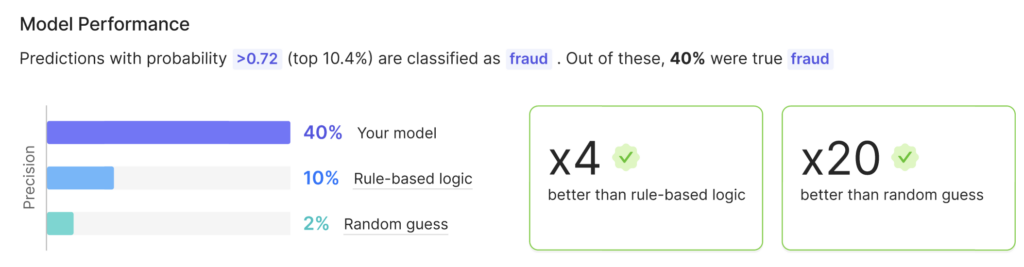
I’ll prove it by showing how a model with 40% precision can be a fantastic model that can drive a lot of revenue for its organization. (Precision is a little different from accuracy; it represents the proportion of positive identifications that the model actually predicted correctly. For example, in the case of customer churn, precision could represent the proportion of customers predicted to churn who actually ended up churning.)
Let’s explore Pecan’s approach for benchmarks.
One benchmark used in Pecan is the random guess, which assumes no business logic is in place. This benchmark just predicts the specific outcome based on how frequently it occurs in the data. For example, if the customer churn rate is 10%, randomly selecting 100 customers would likely include 10 churned customers, resulting in 10% precision. The random guess is also vital as it shows how much better the model is compared to a situation where no sophisticated logic is used to detect a specific outcome.
Another benchmark automatically generated in Pecan is a comparison to rule-based logic, which aims to demonstrate the results provided by a simple analytic approach. It is a simple, single-variable model created using just one column from the data that is strongly correlated to the target.
This simple model serves as a reference point to ensure that the model has sufficient predictive power and can outperform the benchmark. If basing predictions on a single column achieves better results than a complex model that uses robust algorithms and multiple variables, it means there’s a problem with the model that requires further investigation.
For example, imagine we were to build a model to detect fraudulent transactions. Let’s assume we care about maximizing the precision (ensuring the model provides correct predictions when predicting a transaction to be fraud).
If, on average, 2% of transactions are fraudulent, predicting randomly will result in 2% precision. It would be hard to use a rule-based model to achieve good results, due to the variety of fraudulent transactions. Let’s assume this model could provide 10% precision, which is 5X better than nothing.
Now let’s imagine we trained a model with Pecan that used all the past data and a lot of information about each transaction. If our model was able to achieve 40% precision, it outperforms the rule-based model by 4X!
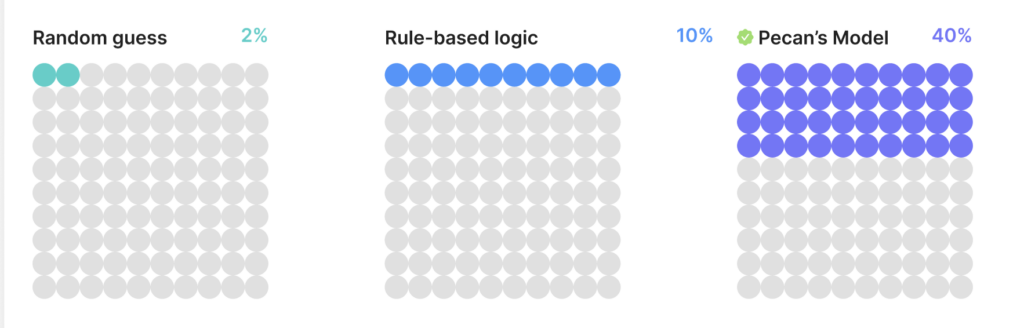
Let’s look at these approaches visually to explore the differences. Assume that every dot is a transaction which is predicted to be “fraud.” When using no logic, statistically, 2 of them will be fraudulent, making the 98 other predictions incorrect. Rule-based logic using simple rules increases precision to 10%. But a fully developed machine-learning model is able to increase precision to 40%.
Health Check #2: The Leakage Test
Why is it important?
Data leakage might be the issue when a model might reach near-perfect results, but when faced with new, unseen data, it fails to provide good results. Data leakage happens when a model accidentally is constructed using features that provide the ‘answers’ while training.
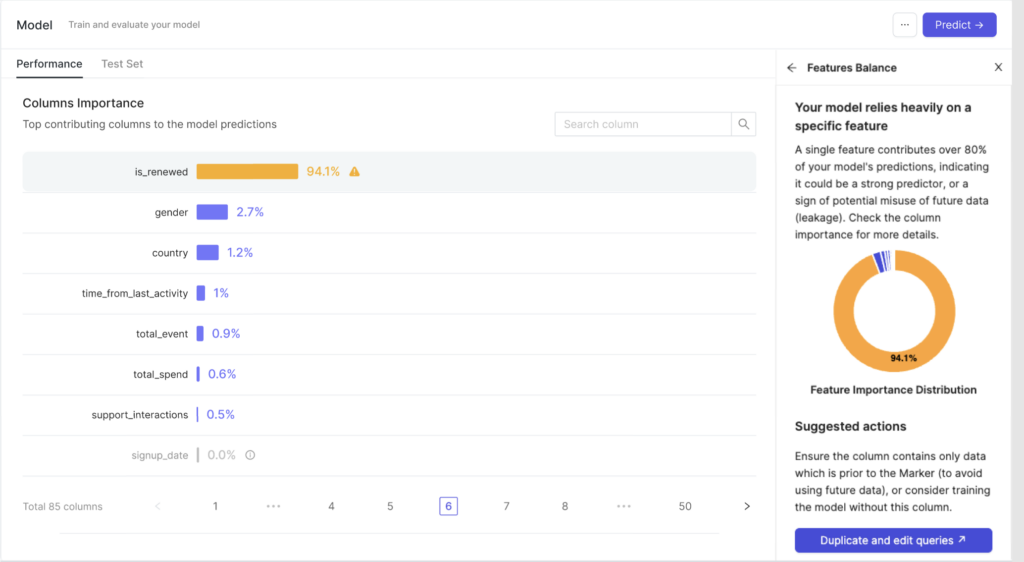
For example, imagine a model that aims to predict if customers will renew their subscription. This model is built with a feature of “is renewed.” The model already has all the information it needs to produce accurate predictions, and so it won’t utilize any other features.
How does Pecan detect and prevent leakage?
Pecan will provide an alert if a single feature shows it is contributing too much information to the model’s predictions by itself (over 50% importance), especially when results come across as too impeccable. This behavior often suggests the single feature is too strong. The “perfect” model is overly relying on it because it provides future data.
To ensure robust model training, Pecan uses the Marker date (the date of prediction) for each entity that gets predictions, coupled with relevant date filters. This approach ensure that only data that’s available up to the moment of prediction is being used by the model when it generates predictions.
Health Check #3: Performance Stability
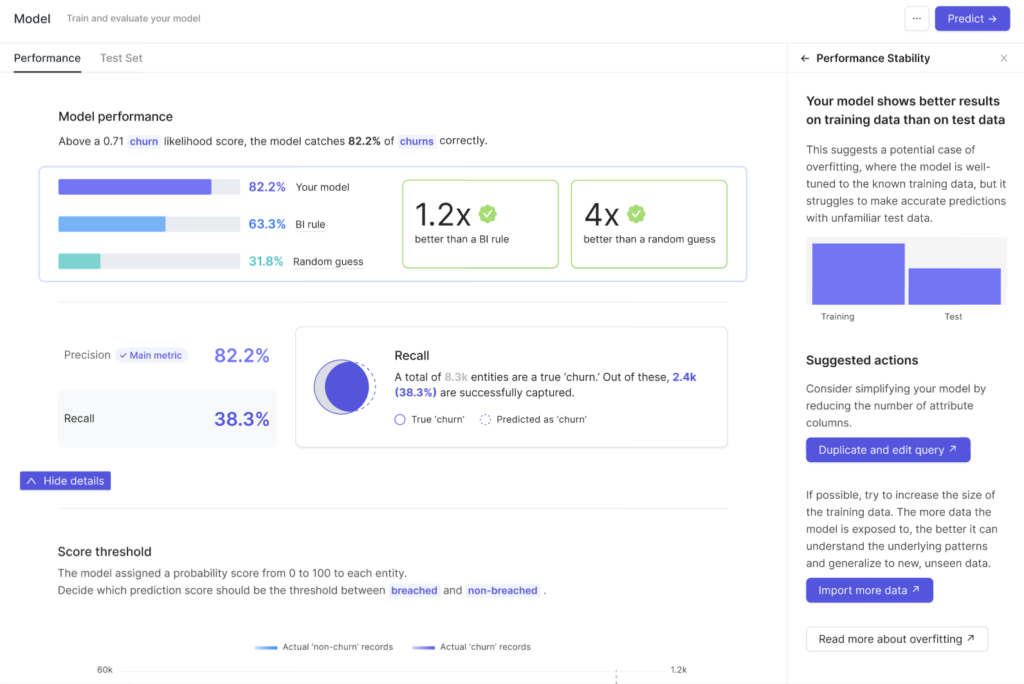
Ever prepared for an exam by memorizing answers to a specific test, only to find yourself failing when given a different set of questions? That’s what overfitting feels like in machine learning.
Overfitting occurs when the model learns the training data too well, capturing noise and outliers, and hence performs poorly on new, unseen data. Keeping a check on performance stability will help you ensure that your model generalizes well to new data.
How does Pecan detect and prevent overfitting?
Performance stability over both training and testing datasets is a vital indicator of a model’s health. When a significant discrepancy between the training set and the test set is found, it may indicate overfitting.
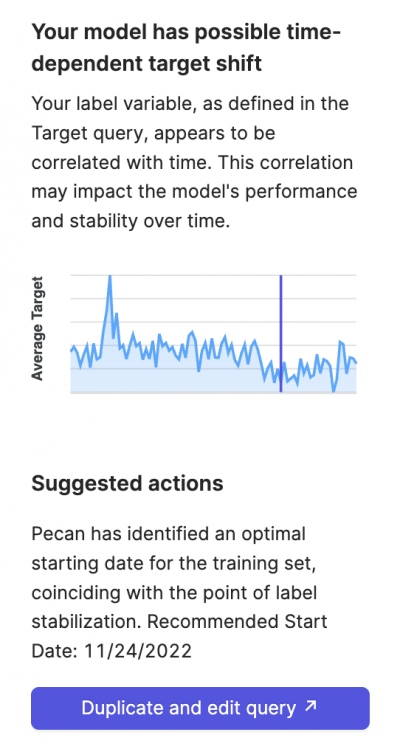
Health Check #4: Target Drift
Machine learning models assume that the distribution of the target variable is stationary, which means it does not change over time. However, in real-world scenarios, this is not always true. For instance, in sales forecasting, the number of sales can increase during holiday seasons, creating a time-related drift in the target variable.
Check out these types of target drift:
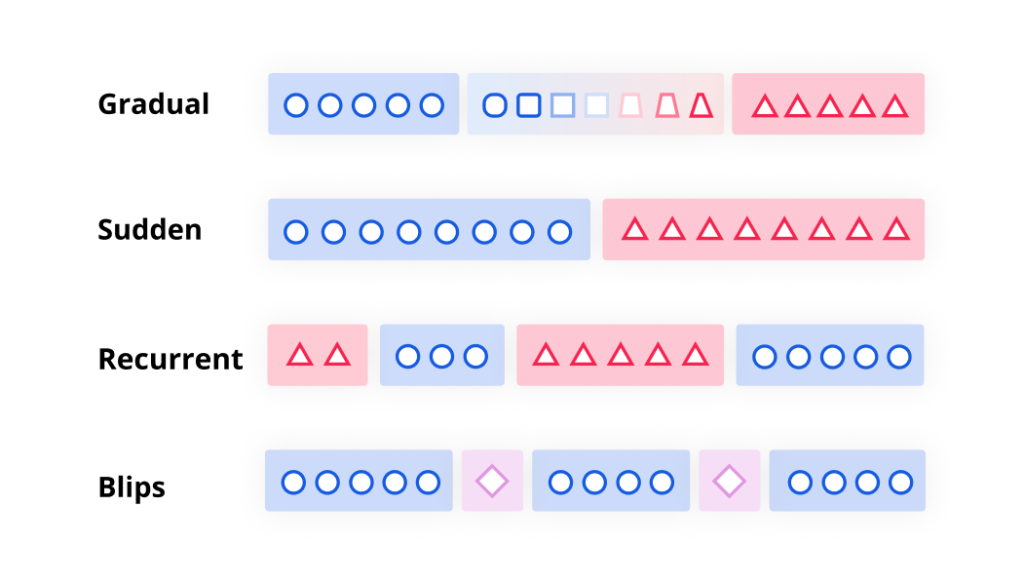
To account for this, Pecan’s platform performs a ‘target drift’ check, which analyzes whether the target variable correlates with time during the training period.
If so, the platform offers a new cut-off point to start the training set, ensuring the model is trained on the most relevant data, improving its accuracy. Sometimes less is more.
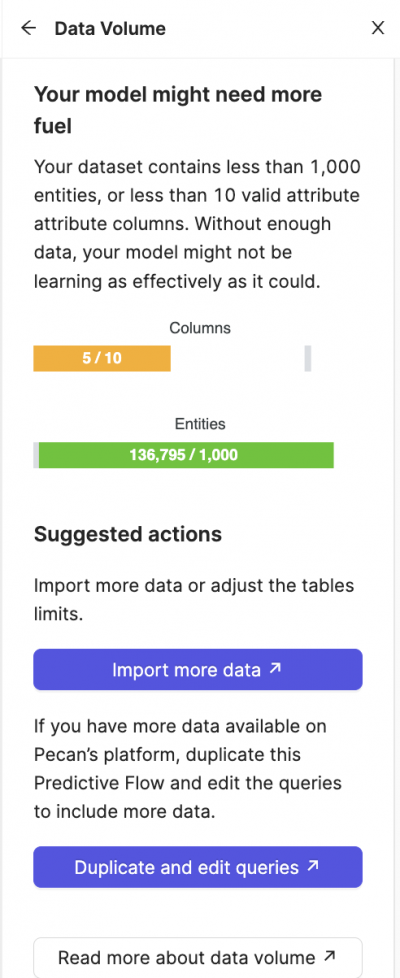
Health Check #5: Data Volume
The size of your dataset is a crucial factor in determining the health of your machine learning model. More data usually results in a more accurate and robust model, given that it can learn from a more comprehensive set of examples.
Pecan recommends a minimum of 1000 entities and 10 valid features (columns) to ensure a healthy model. Pecan drops columns which won’t provide the model with new information. For example, columns will be dropped if their null rate is 99%, if they correlate strongly with another column, or if they have a constant value that’s the same for all rows. If a dataset falls short of 10 valid features, it might be unable to adjust to new data.
A Prescription for Modeling Success
Running and accurately interpreting these health checks are keys to constructing and maintaining robust models. This practice can help ease the process of model evaluation, and suggest fast solutions to common problems.
Once you’ve examined your model’s initial health check results, you can make changes to the data used and the model’s setup easily with Pecan’s platform. The ability to quickly adjust and refine models is a huge plus of a platform like Pecan and an advantage over hand-coding models, where fixing issues can be far more time-consuming, after you’ve already spent a lot of time manually evaluating the model.
With your models healthy and ready to use, you’ll generate predictions that are — as George Box might say — both “less wrong” and very useful for your business, quicker than ever.

















