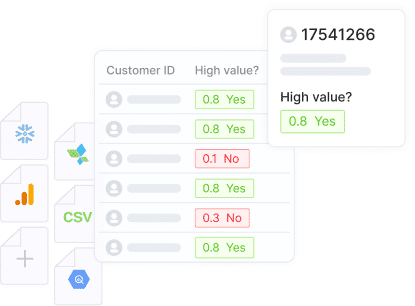
In a nutshell:
- Binary classification models are essential in predictive analytics for making informed decisions and predictions.
- Understanding evaluation metrics like accuracy, precision, recall, and F1 score is crucial for assessing model performance.
- Real-world applications include fraud detection, churn prediction, and conversion prediction.
- Best practices involve data preprocessing, feature engineering, and model evaluation techniques.
- Automated machine learning platforms simplify the process of building and deploying binary classification models for better predictive analytics.
Is it a cat or a dog? Spam or not spam? Hot dog or not a hot dog? The world is full of binary choices, and binary classification models are the gatekeepers that help us make these all-important yes-or-no decisions.
In the realm of machine learning, binary classification models are the ultimate decision-makers, tasked with separating the wheat from the chaff, the ones from the zeroes, and the yeses from the nos. These powerful algorithms sift through vast amounts of data, searching for patterns and clues that can accurately predict which category a given input belongs to.
But don’t let their seemingly simple “this or that” nature fool you. Under the hood, binary classification models employ sophisticated techniques and algorithms. Each approach has its own strengths and weaknesses, and choosing the right model for the job can mean the difference between accurate predictions and costly mistakes.
Let’s explore the underlying concepts and algorithms, delve into evaluation metrics, examine real-world applications, discuss best practices for building and evaluating models, and address the challenges and limitations of binary classification. You’ll learn how this powerful machine-learning approach can lead to some surprisingly strong business results.
The Evolution of Binary Classification Models
Over the years, the field of binary classification has made significant strides. From its humble beginnings using basic logistic regression, binary classification has now evolved to incorporate more complex and sophisticated algorithms such as decision trees, random forests, support vector machines, and neural networks, among others. These improvements have greatly increased the predictive power of binary classification models, allowing for a higher degree of accuracy and reliability in predictions.
The evolution of binary classification models has been closely related to the advancement of computer power and the availability of larger datasets for training. This has made it possible to train more complex models that can handle higher-dimensional data, leading to more nuanced and accurate predictions of the target variable.
The data deluge is real! As information explodes across fields, binary classification models are becoming an invaluable tool for unlocking its secrets. These models excel at sifting through massive datasets to identify patterns and predict two distinct outcomes. From social media analysis to healthcare diagnostics, binary classification is at the forefront of extracting valuable insights and making sense of the world around us.
Finally, the rise of automated and low-code machine learning platforms has democratized the use of binary classification. It has made these powerful predictive tools accessible to non-technical users, breaking the barriers of complexity and technical know-how traditionally associated with machine learning models. As we step into the future, the challenge lies in continually refining these models and techniques, ensuring their robustness amid growing data volumes and evolving real-world scenarios.
Real-World Applications of Binary Classification
Binary classification models are not just theoretical constructs but have practical applications that shape various industries and business decisions. They enable us to predict binary outcomes, a capability that is particularly useful in scenarios where the outcomes are of significant importance. The use of these models extends to fields like fraud detection, churn prediction, and conversion prediction.
Fraud Detection
One of the most common binary classification applications is detecting fraudulent activity. For instance, in banking and finance, these models can predict whether a financial transaction, like a credit card purchase, is legitimate or fraudulent based on a set of input variables. By training the model with historical transactions, it becomes possible to identify patterns indicative of fraud. The model’s output, classifying each transaction as either legitimate or fraudulent, assists in detecting and preventing fraudulent activity, thereby safeguarding the financial assets of individuals and institutions.
Churn Prediction
Another widespread use of binary classification models is in predicting customer churn. Businesses use these models to identify whether a customer is likely to stop using their services or products. The model takes into consideration various factors, such as the customer’s usage pattern, spending behavior, and engagement with the business. By predicting churn, businesses can proactively reach out to at-risk customers with offers or solutions to improve their experience and retain them.
Conversion Prediction
In marketing and sales, binary classification models perform conversion prediction. They can predict whether a prospect or a lead is likely to make a purchase based on their interaction with the business, such as their browsing behavior, past purchases, and response to marketing campaigns. This allows businesses to prioritize and tailor their marketing efforts, leading to an increase in conversion rates and a more efficient utilization of resources.
Binary classification models are the backbone of many intelligent systems and are revolutionizing how businesses operate. They analyze data to categorize information into two groups, enabling data-driven decisions, personalized experiences, and operational efficiency. Understanding these applications unlocks the power of binary classification models as a core technology in predictive analytics.

Best Practices for Building and Evaluating Binary Classification Models
Building and successfully evaluating a binary classification model involves steps that go beyond simply using a pre-defined algorithm. It requires careful data preprocessing, feature engineering, and diligent model evaluation and validation techniques.
Data Preprocessing and Feature Engineering
Data preprocessing creates an accurate binary classification model. It involves cleaning the data to fill in missing values, remove outliers, or deal with irrelevant features. This step ensures that the model learns from high-quality data, which increases its predictive power.
On the other hand, feature engineering involves transforming the raw data into features that the model can better understand and learn from. This could be through encoding categorical variables, creating interaction features, or using domain knowledge to create more meaningful features. Proper feature engineering can significantly boost the model’s performance.
Model Evaluation and Validation Techniques
Once the model is built, the real test comes: how accurate are its predictions? Here’s where metrics like accuracy, precision, recall, and F1 score become your allies. These metrics help you judge how well the model separates the data into the two categories it’s trained for, ensuring it delivers reliable results.
To get a complete picture, validation techniques like k-fold cross-validation or hold-out validation come in handy. These methods provide an unbiased assessment of how well the model performs on unfamiliar data. This is important because we don’t want the model to simply memorize the training data. Instead, we want it to learn and apply patterns so it can accurately predict outcomes on new information. This is what makes the model effective when used in real-world scenarios.
Metrics for Model Evaluation
To effectively gauge the performance of a binary classification model, you must understand various evaluation metrics. These metrics provide insights into the correctness and reliability of the model’s predictions, which are necessary for optimizing its performance or comparing it against other models.
Accuracy, Precision, Recall, and F1 Score
The primary metrics used for evaluating binary classification models are Accuracy, Precision, Recall, and F1 Score.
- Accuracy: This Is the most straightforward metric, calculating the proportion of true results (both true positives and true negatives) in the data. Despite its simplicity, accuracy alone can be misleading, especially in imbalanced data sets.
- Precision: This measures the accuracy of positive predictions made by the model. It essentially shows how many of the predicted positive instances are truly positive.
- Recall: Also called sensitivity, this gauges the model’s ability to find all the positive instances. In other words, it measures the proportion of actual positives correctly identified.
- F1 Score: This metric is the harmonic mean of precision and recall, serving as a balanced measure when the cost of false positives and false negatives are very different. It ranges between 0 and 1, with 1 indicating perfect precision and recall.
ROC Curve and AUC
The Receiver Operating Characteristic (ROC) curve is another common tool for evaluating binary classification models. It plots the true positive rate (recall) against the false positive rate at various threshold settings, allowing analysts to assess the trade-off between sensitivity and specificity.
The Area Under the Curve (AUC) metric comes from the ROC curve. An AUC of 1 signifies a perfect model, while an AUC of 0.5 suggests the model is no better than random guessing.
The ROC-AUC metrics are widely used because they are invariant to class distribution changes, making them very robust for evaluating models trained on imbalanced datasets.
Understanding and effectively employing these metrics enables one to make informed decisions while building and optimizing binary classification models.
Challenges and Limitations of Binary Classification Models
Despite their many advantages, binary classification models come with their own set of challenges and limitations. Two of the most common issues encountered are dealing with imbalanced datasets and handling the dilemma of overfitting and underfitting.
Dealing with Imbalanced Datasets
In a binary classification problem, imbalanced data refers to a situation where one class has significantly more instances than the other. For example, in fraud detection, the number of legitimate transactions is usually much higher than fraudulent ones. Training a model on such data can cause it to become biased towards the majority class, often leading to poor performance when predicting the minority class.
Several strategies exist to handle imbalanced data sets, including resampling methods, cost-sensitive training, or using performance metrics that are less sensitive to class imbalance, such as AUC-ROC.
Overfitting and Underfitting
Overfitting occurs when a model learns the noise and outliers in the training data to the extent that it adversely impacts the performance of unseen data. Conversely, underfitting is when the model is too simple to capture the underlying trend of the data.
Addressing these issues often involves a trade-off. Techniques such as cross-validation, regularization, and pruning can mitigate overfitting while adding more features, using more complex models, or obtaining more training data can help overcome underfitting.
Building an effective binary classification model requires a blend of careful data preprocessing, feature engineering, and proper model evaluation and validation techniques. Furthermore, being mindful of the challenges and limitations can help you build robust and reliable models. This knowledge is essential for any data analyst or data scientist looking to leverage the powerful technique of binary classification in their work.

Easing Implementation with an Automated, Low-Code Machine Learning Platform
While the process of developing, testing, and deploying a binary classification model can be complex, advancements in machine learning (ML) have provided solutions that simplify these tasks. Automated machine learning platforms, particularly those with low-code or no-code interfaces, offer an accessible way for even non-technical users to harness the power of binary classification models.
The Availability of Automated Platforms, Even for Less Technical Users
An automated machine learning platform that offers low-code or no-code functionalities can guide users through the process of creating and evaluating binary classification models. These platforms integrate automated data preprocessing, model selection and tuning, and validation steps into a simplified, easy-to-use interface. Such platforms can drastically reduce the time and technical know-how required to build an effective binary classification model.
For instance, these automated platforms handle tasks like missing value imputation, outlier detection, and feature engineering, preventing common errors during data preprocessing. They also automatically select the optimal algorithms and hyperparameters for the model, eliminating the need for manual trial and error. These platforms use robust model validation techniques to ensure the final model’s generalizability to unseen data.
Choosing a Platform That Still Offers Insights into Modeling and Explainability for Finished Models
While the convenience of an automated ML platform is undeniable, choosing one that still offers insights into the modeling process and explainability for the finished models and their predictions is critical. This transparency is key to understanding how the model makes predictions and diagnosing potential issues that could affect its performance.
Explainability can help stakeholders trust the model’s predictions, especially in high-stakes applications like healthcare or finance, where the cost of errors can be significant. It’s imperative to ensure that even with simplified model-building processes, there’s still visibility and understanding of what goes on under the hood.
By leveraging an automated, low-code machine learning platform, you can simplify the process of building and deploying binary classification models and make them accessible to a broader audience. This accessibility can democratize machine learning, enabling more businesses and organizations to harness the power of binary classification for their predictive analytics needs.
Leveraging Binary Classification for Better Predictive Analytics
Binary classification has become a pivotal tool in predictive analytics. Its core role lies in predicting binary outcomes, enabling decision-makers in various fields to make data-driven choices. Binary classification models offer tremendous benefits, from detecting fraudulent activity in banking to predicting customer churn in business and even facilitating marketing efforts through conversion prediction.
Binary classification models present an incredible opportunity for data analysts, data scientists, and even individuals with little to no technical background. From predicting customer behavior to detecting fraudulent activity, binary classification models have found their place in a multitude of industries.
Whether you are an expert in data science or a less technical user, incorporating binary classification models into your work can significantly enhance your predictive analytics capabilities. Leverage this powerful tool to refine your decision-making process, optimize your operations, and ultimately, drive your business or field forward. By understanding the potential that binary classification models hold, you are taking a step toward making more informed, data-driven decisions.
Build a binary classification model now! Get a tour of Pecan today and you’ll have a finished model quicker than you dreamed possible. You’ll get those dogs and cats sorted out in no time!