
- In a nutshell:ChatGPT is a powerful language model that can generate human-like text and provide insights into predictive analytics.
- It can offer guidance and code for data processing and feature creation, but can miss critical concepts like weekly sampling and active user inclusion.
- ChatGPT has strengths in educating on machine learning and generating innovative features, but it can generate erroneous code and introduce data leakage.
- Pecan's platform offers a more comprehensive solution for data handling and support for various data types in predictive analytics.
- Advanced language models can potentially be a valuable data science tool, but caution and validation are necessary for real-world applications.
Recent years have brought incredible advancements in the fascinating realm of artificial intelligence. You might have heard of a language model named ChatGPT (and if you haven’t, maybe you’re living on the moon). It’s equipped with extraordinary powers of understanding and generating human-like text. It's touted as an exceptional tool for customer service, education, personal productivity, creative content, personalization, and even translation. But alongside recent AI marvels, questions emerge: Can GPT replace data analysts? Can language models do data science beyond natural language processing? Can they optimize our work with data? In this blog, we’ll explore the strengths, limitations, and potential applications of ChatGPT in the realm of predictive analytics and focus on the question: Can ChatGPT tackle the exciting world — but challenging tasks — of predictive analytics? We set out on a mission to put ChatGPT to the test. We wanted to see if it could handle questions requiring predictive models built on historical data. We were curious to see where ChatGPT might succeed and where it might stumble. Could it interpret the numbers and pull the correct information from the data? Or would it slip up and miss crucial details that matter?
What is predictive analytics?
Predictive analytics uses data, statistics, and machine learning techniques to build analytical models that can generate predictions about what will happen in the future. Predictive models learn to spot patterns and trends in historical data. Then, they can look at new data they haven’t seen before and seek out those same patterns. Industries like banking, insurance, retail, CPG, manufacturing, e-commerce, food and beverage, and more all use predictive analytics.
Defining a predictive question for ChatGPT
We asked ChatGPT to produce an AI-ready dataset that could be used to train a decision tree-based model. The model should predict an answer to the following question: “Predicting every week, what is the likelihood that an active customer during the past 100 days will continue doing an activity within the next 180 days?” (An active customer is a customer who made a transaction.)



ChatGPT provided valuable insights and recommendations on the essential steps required to build a predictive model. However, it’s important to note that ChatGPT can offer guidance and code for these steps, but it cannot directly manipulate your data. With that in mind, let’s proceed by requesting ChatGPT to generate the necessary code for implementing the recommended procedures.Initial data processing
We would like ChatGPT to begin generating the code to actually process the data.

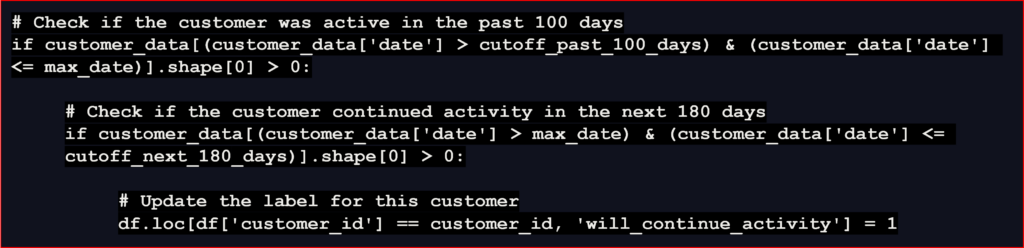
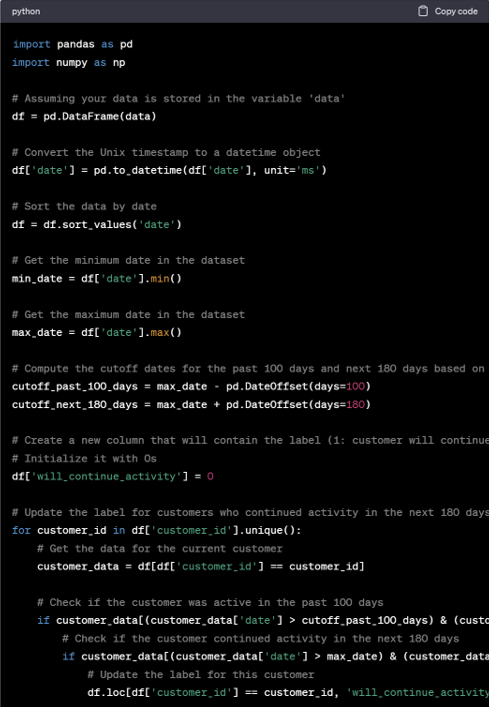
Initially, the code generated appears promising. However, we specifically requested that the predictions be made at the weekly level, a detail that has been overlooked by ChatGPT. It’s crucial to construct the training set with a record for each week, rather than per individual transaction. If implemented as-is, the proposed solution would yield a poorly performing model. That’s because of the potential sampling bias introduced by weighting users based on their transaction count. Such an approach would disproportionately favor customers with higher transaction volumes, introducing significant bias into the model. We remind our AI colleague to ensure sampling every week.
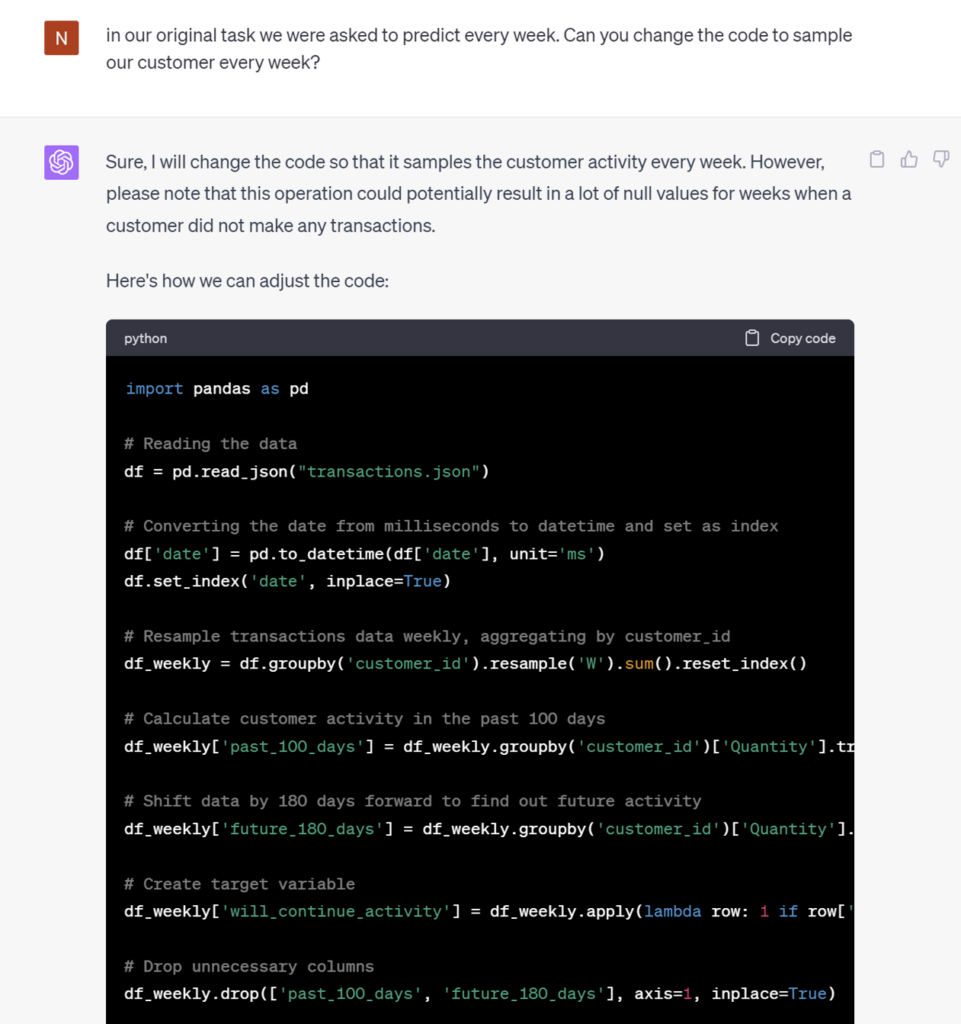
We are conducting weekly sampling; however, ChatGPT overlooked our intention to predict outcomes for active users. Let’s gently remind it about this specific requirement. A little nudge was all it took to align everything.
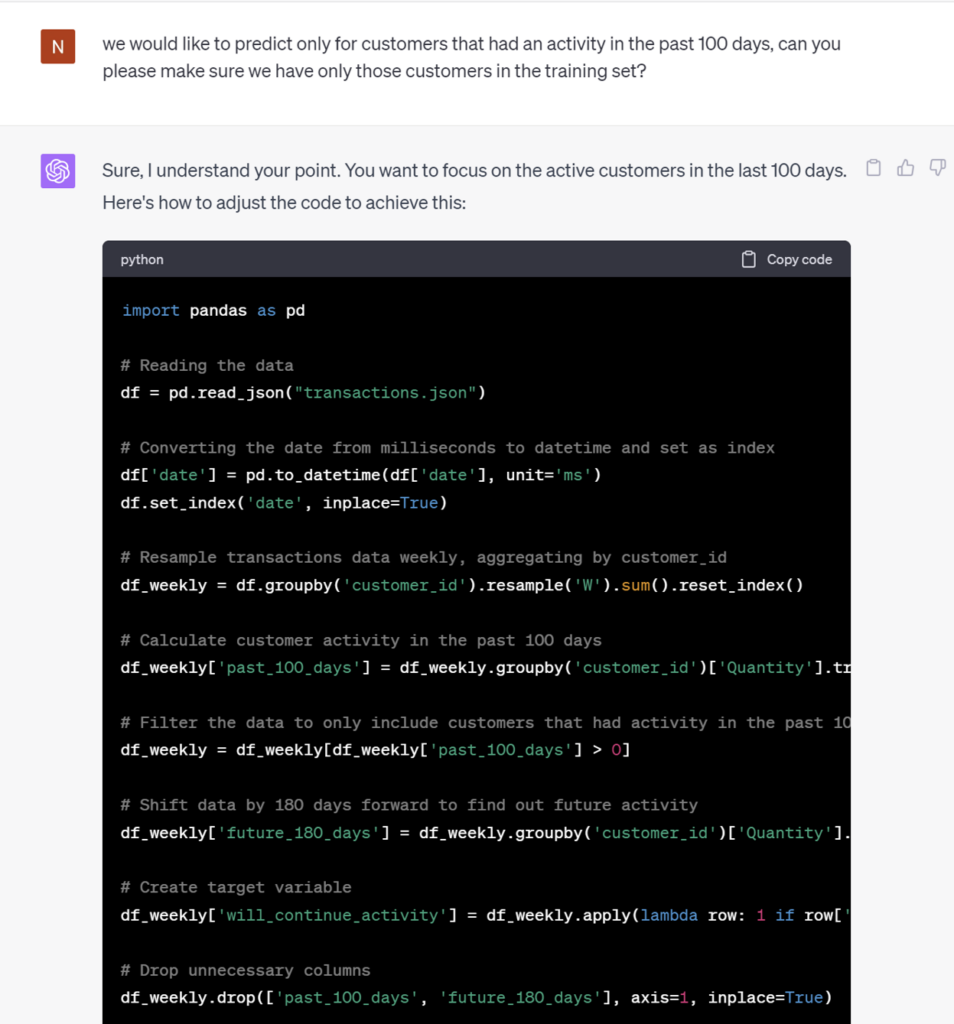
ChatGPT successfully handled the initial data preparation tasks; however, it inadvertently overlooked essential steps such as weekly sampling and the inclusion of only active users. As a result, we found it necessary to provide ChatGPT with gentle reminders about these critical concepts.Features and data leakage
Having successfully curated the dataset for our model’s learning purposes, let’s proceed to the next pivotal phase – the creation of features. Features are the variables or attributes used to predict outcomes or model future events. These data inputs feed into predictive models, allowing them to identify complex patterns and correlations within the historical data. The models can then make accurate predictions about future events or outcomes using entirely new and unseen data.
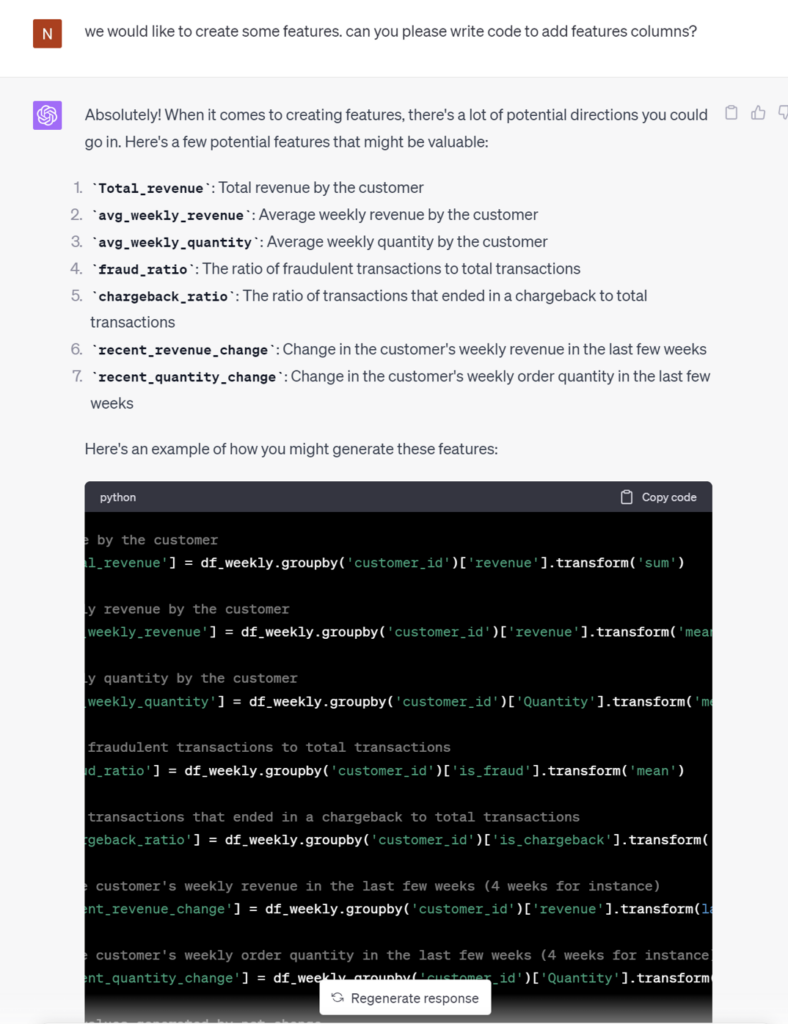
ChatGPT generated some valuable code for creating features. These features are essential to the performance of the predictive model. They need to be relevant to the outcome that’s being predicted, and they need to accurately represent something meaningful in the data. Choosing features well will provide more precise predictions, but adding irrelevant features will introduce noise to the model and make it less useful. Remarkably, ChatGPT explained the formulation of these features well, much as an accomplished data scientist would. However, we must also evaluate its work with regard to a critical consideration when crafting features: the risk of data leakage. It’s vital to avoid incorporating future information when predicting events, as this could lead to predictions that seem accurate – but are produced by a model that has more information about the future than it will have when it’s put into use. Unfortunately, ChatGPT missed this important issue. In our next step, let’s offer a friendly reminder to ensure this concern is effectively addressed. With a little help, ChatGPT does a great job!
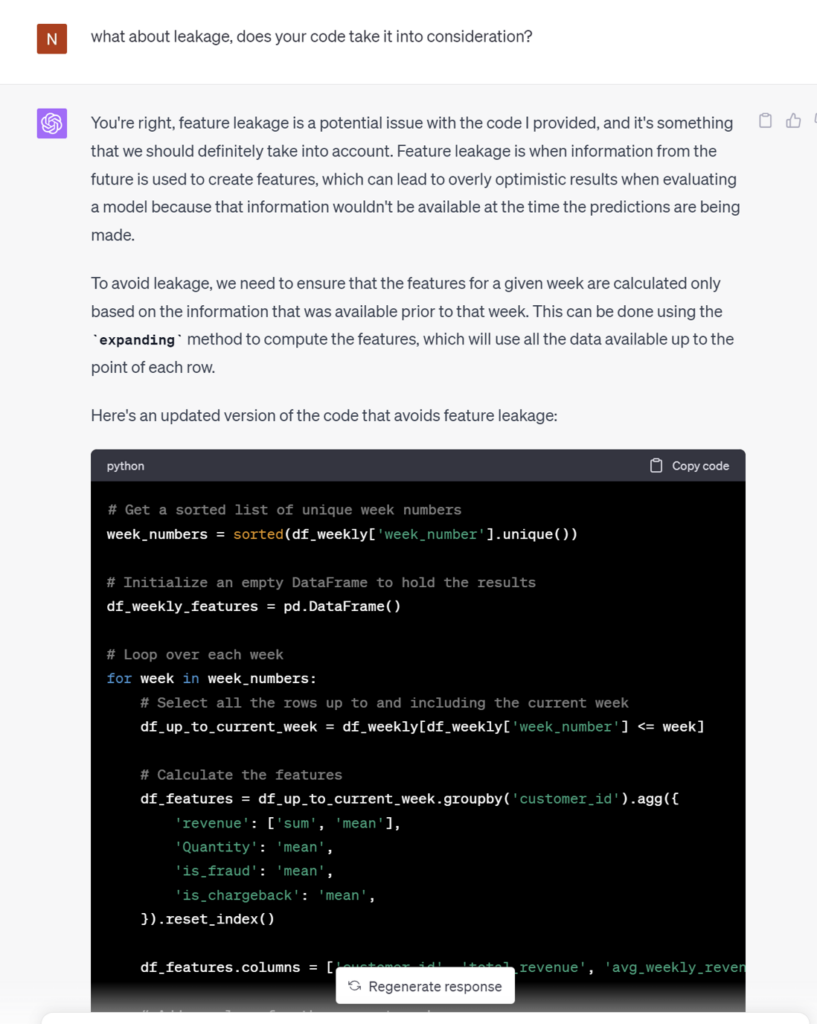
ChatGPT has effectively generated valuable code for creating essential features, a critical aspect of predictive modeling. However, it failed to address the risk of data leakage, a crucial concern. Despite this, with some guidance, ChatGPT has the potential to excel as a valuable data science tool.Strengths, limitations, and potential applications
ChatGPT proves to be an exceptional educator. It can share a wealth of knowledge on machine learning and predictive analytics, and give suggestions about data handling, flow, and model usage. Access to this knowledge can be a valuable performance booster with real impact for seasoned data scientists and tech experts. However, after our experience here, we’d advise caution for those unfamiliar with machine learning. ChatGPT may generate erroneous code or impractical suggestions. While it can handle some simple predictive analytics tasks on datasets that are already AI-ready, ChatGPT thrives when it provides insightful data understanding and structuring. Moreover, it shines as an incredible tool for generating innovative features from existing data. However, implementation challenges may arise when dealing with complex, unorganized datasets or unclear user predictive queries. Despite its impressive capabilities, ChatGPT has some notable drawbacks that users should be aware of. First, the Python code generated by ChatGPT can be prone to bugs, potentially leading to unexpected errors and inefficiencies. Second, ChatGPT occasionally fails to adhere to its own machine-learning guidelines. It will even provide code that introduces data leakage into models, despite explicitly offering cautions when it is asked about this concern. Additionally, ChatGPT may incorrectly calculate labels and use improper sampling practices, like selecting users on a monthly basis or misusing transaction data. These limitations highlight the importance of scrutiny and validation when leveraging ChatGPT’s output for real-world applications.
How is ChatGPT different from what Pecan offers?
In comparison to Pecan’s platform, ChatGPT exhibits certain limitations. Using Pecan, you can be assured that the model you receive is suitable for real-world applications and safe for use in production. ChatGPT primarily offers Python code, which is advantageous for data scientists, but not as practical for analysts skilled in SQL. ChatGPT struggles with big data, often generating inefficient code for such tasks and offering unclear guidance for users wanting to prepare the available data for AI. Meanwhile, Pecan’s platform caters to messy data, offering efficient data structuring and automated creation of AI-ready datasets, including support for big data. Pecan’s platform, with its focus on data handling and support for various data types, provides a more comprehensive solution for those dealing with large and complex datasets, offering enhanced flexibility and efficiency in data preparation for AI applications.
The outcome: Can ChatGPT do predictive analytics?
Ready to get started with building a predictive analytics model yourself to make a real impact? Then go ahead and start your free trial. Or, if you’d prefer, we can give you a guided tour.






