Do you ever wish you could hire one of those home organizers from a TV series — but have them clean up your business’s data instead? KonMari your untidy tables so they spark joy again? Do a Home Edit on your duplicate rows?
Yes, your data is probably messy. But that’s OK. With the amount of data collected by organizations today, there’s no shame in less-than-perfect data. Fortunately, new approaches mean you can automatically discover common data problems so you can move AI projects forward efficiently.
We’re excited to share what we’re doing at Pecan to make the power of automated data exploration available to our customers. This approach saves time and money in the AI process and makes your predictive results more reliable.
The Dirty Data Problem
The shortage of data scientists and a lack of data strategy are often cited as significant challenges to data science. But a third concern actually topped the list of issues in a recent survey of over 16,000 data professionals: dirty data.
Dirty data can have many problems that can be challenging to identify and address. We’ve pulled together the list below to share the issues we see most frequently in our customers’ data.

These issues aren’t just in a small spreadsheet of data you could manually edit. Instead, these problems are present across massive quantities of data. In reality, when we build predictive models for our customers, we use a lot of data — say, 10 TB, 40+ tables, and 200+ relevant columns. All that data is useful for Pecan as it predicts the future. When we combine data from multiple sources in the Pecan platform, it can be hard to track its quality.
The data that goes into an AI model must be clean, logically constructed, balanced, and valid. It also needs to be reviewed carefully to avoid potential target leakage. Well-prepared data cuts down on the time and computation required to optimize models.
Overall, good inputs lead to rapid, reliable outputs. These requirements mean we need robust tools to automatically review these large amounts of data and check their validity.
Automating Data Discovery
Because a high level of data preparation is necessary for successful AI, we ensure that customer data is thoroughly analyzed and tidied as part of our data preparation process. In traditional data science approaches, a data scientist would spend a lot of time manually exploring data. They would generate and review various statistics and visualizations to look for potential concerns. This process is often called exploratory data analysis or EDA.
We wanted to improve the manual EDA process and make it faster and easier for our analysts to address dirty data. With our team’s automated EDA process, we can rapidly detect problems and view visualizations to reveal concerns, whether in one table or multiple tables, and even over time.
Revealing Issues Through Data Visualizations
For example, the visualization below helped our Pecan experts quickly detect an issue in app user data. When looking at data for users who made a purchase in an app, we would expect to also see a session identifier for each of those users in our session data. After all, it’s hard to buy something in an app if you’re not using it! Typically, you would connect a table of purchase data to a table of session identifiers by linking them through the user IDs present in both.
The diagram below — generated in our automated EDA process — quickly revealed a problem with the logic used to connect these data tables. The tables of data that represented purchases and that represented sessions had not been connected properly. In fact, the diagram below should have shown the purchases circle entirely within the sessions circle, not just displayed a small overlap.
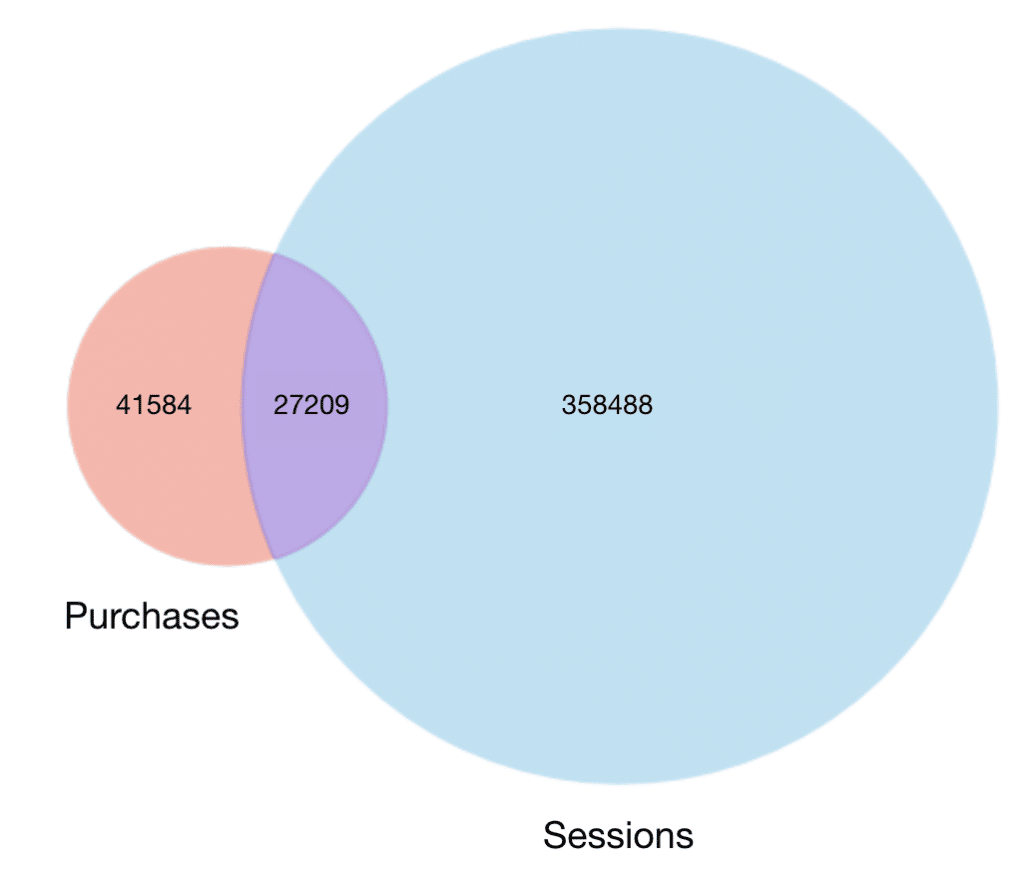
Because they had quick access to this visualization, our analysts could address this issue and fix the logic well before any other feature engineering or modeling steps had begun.
The visualization below also provided important information about a customer’s data in advance of modeling. The spike in the customer’s data is plainly obvious with the help of this plot. If we’d tried to build a model with this problematic data, we might have seen overfitting as a result. However, with our automated data exploration tools, our Pecan expert caught the issue in time and reviewed the concerns with the customer.
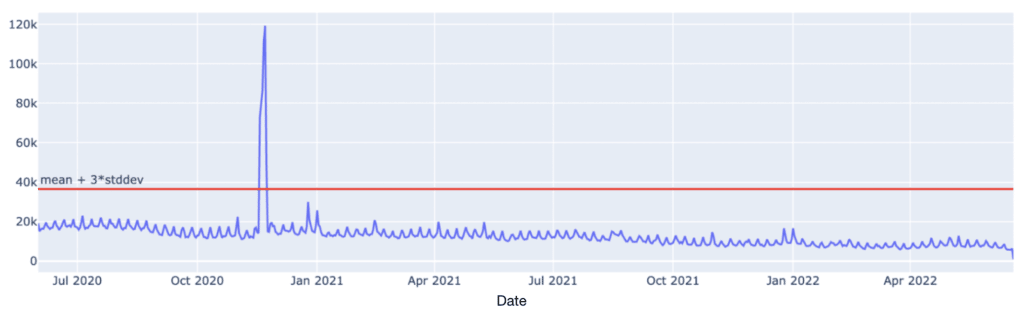
The source of the problem? Duplicated rows of data. It’s a common issue, but it’s vital to address it before proceeding further in the machine-learning process.
Accelerating AI Success with Automated EDA
This time-saving, automated approach moves the team faster toward building high-value AI models with accurate, impactful results. And, as anyone who has ever examined data manually can attest, automated assistance in the EDA process is not just time-saving — it’s sanity-saving, too! Chasing down odd issues in dirty data can be hugely stressful and tedious.
Additionally, removing data that can’t be used for predictive modeling is essential for streamlining the model building and evaluation process. Carrying unusable data throughout a machine learning pipeline makes the process take longer and incurs greater compute costs. As a result, automated EDA and better data cleaning are also money savers.
With automated data exploration that helps rapidly identify significant issues in your data, you’ll get better AI models, obtain more reliable results, and see a greater impact on your business. You probably won’t get a Netflix series out of your data cleanup, but you’ll be a predictive modeling star.
Want to learn more about using your data for predictive modeling? Read about whether your data is ready for predictive modeling, and learn more about The What and Why of Predictive Analytics to see how data is used to build different kinds of models that support business outcomes.
Ready to learn more about Pecan’s state-of-the-art approach to automated predictive analytics? Get in touch for a quick, easy use-case consultation. We’ll help you find the best way to get future-ready.